🧠 Memory Definition in LLM Applications
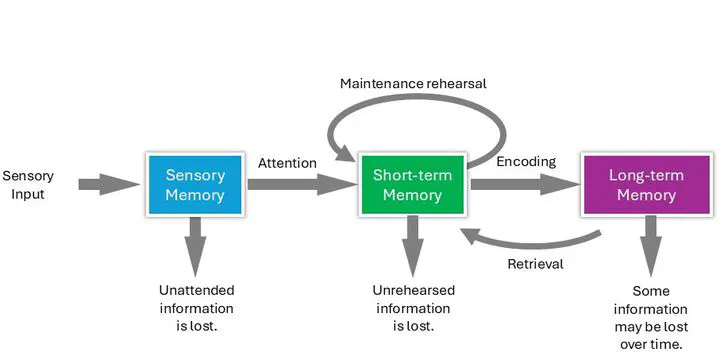 Dual-Trace Hypothesis
Dual-Trace HypothesisFinal Goal Definition
How to Train a Personalized Model
Different people have different memories. People also have different paths in thinking and decision-making based on their unique experiences. The ultimate goal is to generate personalized models.
The actual work involves reverse engineering, using data generated by the model to infer the model itself (reversely generating a “personalized model” from the “individual data” inferred by the human brain in real environments).
Models and training data are equivalent; the model is a compression of the training data.
To achieve the final goal, the model must be capable of on-device real-time learning, requiring a breakthrough in the current training -> inference paradigm. Training and inference must be integrated, with two core challenges:
Real-time Updates (Incremental Training)
The training process of statistical models is essentially a process of mapping from one sample distribution to another.
Incremental training (adding new knowledge) can lead to catastrophic forgetting due to the model’s strong learning ability and rapid overfitting.
Traditional solutions involve including the original sample distribution with each incremental training, which is costly and prevents real-time incremental training.
This has led to the current paradigm where training and inference are separate, preventing real-time updates.
De-averaging Individual Data
- Each user’s detailed record is just a drop in the ocean relative to the overall training data. It is crucial to precisely recall each data detail as needed, ensuring that incremental personal data is de-averaged within the statistical model.
Simplified Mid-term Goal
Directly achieving the final goal is too difficult, so a mid-term goal must be defined to pave the way toward the ultimate goal.
The mid-term goal is defined as layering individual data (long-term memory) on top of a foundational model (pre-trained LLM). To simplify the problem, real-time model updates are not considered, focusing instead on how a small amount of individual data can be better represented in the LLM, i.e., de-averaging individual data within the LLM.
Excluding real-time model updates means that under the premise of freezing the main network of the model, the incremental individual data is stored externally and updated in real-time in a way that the model can perceive. There are three potential technical paths for data storage:
- RAG, an external library.
- Long context window.
- Personal data stored parametrically, in some form of bypass network (form unknown).
Modern computers are built on Turing machines and von Neumann architecture, with AIGOS built on LLMs representing the Turing machine’s read/write head, analogous to the human brain’s prefrontal cortex.
Memory should be that infinitely long paper tape, where “experiences, documents, images, languages” should be placed on this infinitely long paper tape.
Omne can be understood as the “control rule TABLE” of the Turing machine.
The next section, “Definition of Long-Term Memory,” answers the question of what long-term memory is.
Definition of Long-Term Memory
What is Long-Term Memory?
Different people have different understandings of the term “long-term memory.” Many papers mention “long-term memory” in their titles, but the term refers to different concepts in different papers. So, what do we understand long-term memory to be?
In our scenario, long-term memory refers to all of the user’s personalized data.
More clearly, long-term memory is defined as historical individual data that impacts future predictions.
This data should convey the most information with the fewest tokens when needed.
Low information entropy data like repetitive phrases should be forgotten or merged and summarized.
What is Implicit Memory?
“Implicit memory” also suffers from terminological confusion. In traditional brain science, implicit memory refers to muscle memory, subconsciousness, etc. But what do we understand implicit memory to be?
The original long-term memory is raw data. Personal long-term memory is compressed and stored after subjective human processing. In our understanding, “implicit memory” refers to the data processed from the raw data (including the processes and methods used for processing). This processed data becomes an untransferable core asset, creating competitive barriers.
In our context, what we refer to as long-term memory actually means implicit memory.
Review of Definitions
- In our context, personalized data, long-term memory, and implicit memory all refer to individual data that has been effectively organized and impacts future predictions.
Business Scenario Definition
Tanka
- In enterprise services, an employee’s job memory includes IM chat history, email records, video conference recordings—essentially, all the data related to their external communications in that role. Based on this job-related data, smart-reply can be implemented in dialogue scenarios to provide response suggestions.
Newsbang
- Deep questions, such as asking about NVIDIA’s stock price, require various background information and historical decision-making bases and paths accumulated over time. These inputs can be understood as long-term memory. The more diverse the input dimensions, the better the questions that can be asked.
Theta
- Combining the user’s infinitely long multimodal health record data, relevant inspection and examination indicators can be found based on the scenario and user queries, and these can be input as context into the model to generate personalized, objective health recommendations.
Commonality Across Scenarios
- Fundamentally, these business scenarios involve using the full range of long-term memory data according to user queries to build an accurate context prompt for the LLM. Through this prompt, specific parameters in the LLM are activated to guide content generation and attention.
Technical Goal Definition
How to Extract Long-Term Memory (Encoding)
- How can we extract and summarize (influential for future use) essential information from daily massive data to form long-term memory?
How to Store Long-Term Memory (Storing)
Data Storage Format
Raw Data
Vectors
Parameters
Graphs
Graphs can be understood as the distillation of LLM model weights, providing visualization and interpretability of key concepts within the LLM.
However, the process of generating graphs from LLM may be insufficient, resulting in significant discrepancies between the generated graph edges and reality.
How to Use Long-Term Memory (Retrieving)
The original user data should be stored as is, with the capability to retrieve it based on business needs according to specific business goals.
Our optimization goal is to better answer the current query by leveraging relevant long-term memory.
The retrieved information should be more relevant and as comprehensive as possible.
The information density should be high, expressing as much information as possible with as few tokens as possible.
Technically, this is a process of diffusion followed by convergence.
Diffusion: In a fully connected network of all information nodes (such as concepts), gather as much information as possible with the fewest steps.
Convergence: Multi-round summarization (a strong suit of many large models) -> which may lead to information loss.
The research focus is on how to store data to achieve higher diffusion efficiency and more complete relevance coverage.
How to Construct a Self-Boosting Flywheel
For a company’s or individual’s data, what types of data combined with LLMs can yield better results?
It is necessary to build an end-to-end memory system (note: system, not model). The model is the prefrontal cortex of this memory system.
The system needs the ability to receive signal inputs and autonomously select what needs to be remembered at any time and place.
It should be able to dynamically determine whether to activate stored memories under different external environments and retrieve relevant memories when needed to integrate them into the output feedback to the external environment.
Place the model in an online learning system that continuously interacts with the external environment. This system determines what information needs to be retained and adjusts the model to adapt to or remember relevant information.
In this process, the model is regulated and dynamically migrated.
Identification of Technical Challenges
How to Extract Long-Term Memory (Encoding)
- Memory involves many different modalities of data, including text, voice, video, etc. How can these different modalities be efficiently encoded according to the scenario?
How to Store Long-Term Memory (Storing)
- How should data forgetting be handled?
How to Use Long-Term Memory (Retrieving)
How can relevant memories be retrieved (memory associations are not only about textual similarity)?
It is necessary to precisely recall the needed memory information (concise and relevant) while satisfying a certain degree of divergence when the model performs multi-hop complex logic.
The trade-off between the breadth of diffusion and relevance to the problem.
How to Construct a Self-Boosting Flywheel
How can we simulate the environment in an irregular system?
How can the agent self-evolve?
Collaboration with Tsinghua University
How to construct training data
How to synthesize training data
Collaboration with Shanghai Jiao Tong University
How to design the loss function
Exploration of Technical Paths
Memory Vectorization: Training an External Memory Model Jointly with a Parameter-Frozen LLM (RAG 2.0)
RAG retrieval is currently the fundamental means of interaction between memory and large models. Enhancing RAG, or “surpassing RAG,” is a mainstream research direction.
Retrieval cannot solve the reasoning cognition problem of agents; other methods are needed. RAG is also not a precise means of outputting exact answers, much less a method for preferences and recommendations.
Related Papers
Improving Language Models by Retrieving from Trillions of Tokens
- Paper Link
- Vector representation + retrieval + cross-attention fusion
MemoryBank: Enhancing Large Language Models with Long-Term Memory
- Paper Link
- One of the earliest studies on providing long-term memory to large models.
USER-LLM: Efficient LLM Contextualization with User Embeddings
- Paper Link
- Segments user input history into chunks using an autoregressive encoder, then encodes and fuses with LLM through cross-attention.
Beyond Retrieval: Embracing Compressive Memory in Real-World Long-Term Conversations
- Paper Link
- COMEDY does not use a retrieval module or memory database but uses a single language model to manage all tasks from generating and compressing memory to generating responses.
Augmenting Language Models with Long-Term Memory
- Paper Link
- Proposes the LongMem framework, slicing long text inputs and storing them in a memory bank, with a sidetree designed to fuse memory through qkv to solve the memory staleness problem.
MEMORYLLM: Towards Self-Updatable Large Language Models
- Paper Link
- Adds a layer of Memory tokens to each layer of transformers, simulating human forgetting by discarding some model parameters when updating to gain new knowledge.
AriGraph: Learning Knowledge Graph World Models with Episodic Memory for LLM Agents
- Paper Link
- Introduces a memory architecture called AriGraph that integrates semantic and episodic memory into a knowledge graph to enhance the reasoning and planning capabilities of LLM-based agents.
Toward Conversational Agents with Context and Time Sensitive Long-term Memory
- Paper Link
- Aims to solve the problem where large language models struggle to focus on the relevant parts of text while ignoring others.
Octopus
Long Context
Kimi refers to long context as the “memory” of a computer.
Too long a context can lead to context pollution, where attention is rendered ineffective.
Large models are essentially performing meta-learning when processing context.
Related Papers
- Memory³: Language Modeling with Explicit Memory
- Paper Link
- Stores knowledge bases (or any text dataset) in sparse attention key-value pairs on drives or non-volatile storage devices.
Memory Parameterization
Update Model Weights in the Form of SFT to Learn New Knowledge
- RTG
- By adding COT data, the ability to generate multi-hop reasoning is learned, automatically finding more relevant context from within the model’s internal knowledge base.
Related Papers
- Think-in-Memory: Recalling and Post-thinking Enable LLMs with Long-Term Memory
- Paper Link
- Proposes the TiM framework, storing memory with a hash table, updating the hash table through insert, forget, and merge operations, retrieving through hash, and integrating it into the LLM via LoRA.
Locate Raw Facts in LLM Features and Then Perform Local Parameter Updates
New Network Structures
- MAMBA
- TTT
- KANs
- xLSTM
- xLSTM: Extended Long Short-Term Memory
Evaluation
- Needles in Haystack?
- How to design evaluation goals?